VDB Overview
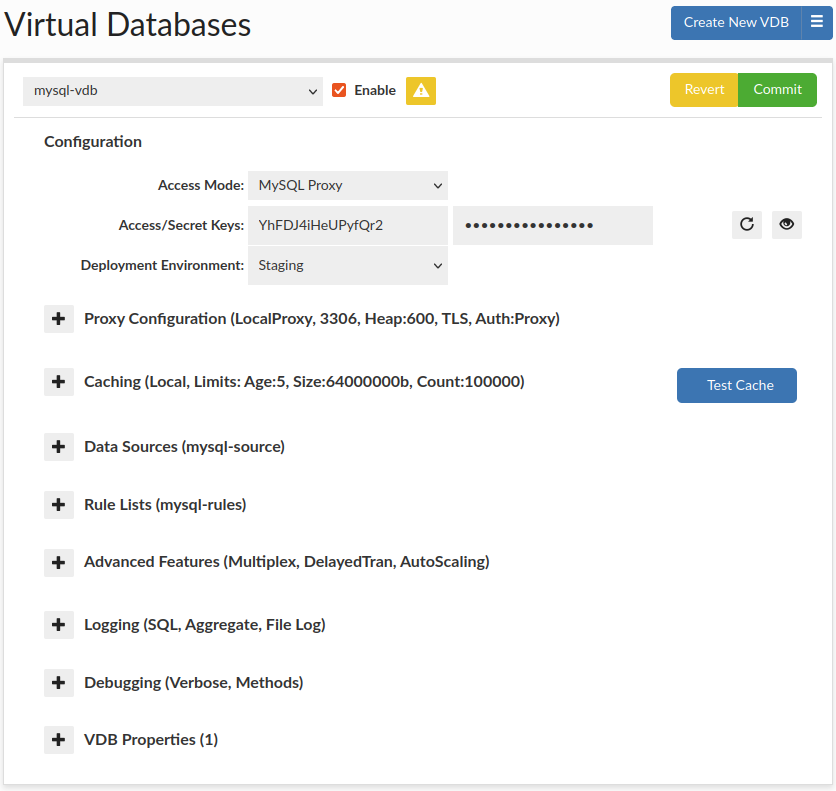
Virtual Databases (VDB) are the basic container for configurations, and aggregate all the settings that will apply to any traffic passed through the VDB. There are two ways to access a VDB, first via JDBC, which supports any JDBC compliant data source, or via a protocol level proxy. In proxy mode, a separate process will be created, and database traffic would be routed through this proxy using a specific port
Enabled: if unchecked, this will result in a proxy disabling access via the port specified. In JDBC mode, this will result in an SQL exception being thrown on a new connection attempt.
Access/Secret Keys: These are generally used in distributed proxy or JDBC mode to provide a shared user/password to allow the remote proxies to pull the complete vdb configuration.
Access Mode: The first step in configuring a VDB is to select the access mode, which will adjust what options are presented, to simplify the configuration:
Deployment Environment: Records the deployment environment of a VDB, supported values: {Development, Staging, User Acceptance Testing, Production}. Groups VDBs by environment within Status tab.

JDBC Configuration

When in JDBC mode, a JDBC URL is provided in the GUI, which is used to configure the application to access the Heimdall Data Access Layer. The JDBC URL is of the format:
JDBC:heimdall://IP:port/{vdb name}?
Optionally, several parameters can be used in conjunction with the Heimdall Connect string:
- hduser={username}: The username to authenticate against the Heimdall server with.
- hdpassword={password}: The password for the Heimdall server, again overriding the parameter in the data source.
- user={username}: The username to use to authenticate against the database with. If the event the hduser is not specified, this will ALSO be used as the default hduser value, in cases where the users on both match.
- password={password}: The password for the database server. In the case where the hdpassword is not specified, this will also be used as the default hdpassword. Note: When using the user and password, the data source credentials will still be used for health checking the application and should have appropriate access for this task.
Note: Typically, only the hduser and hdpassword is used in the Heimdall JDBC URL, as the data source can provide the user and password options. The ability to specify this here is to allow applications to specify their own username and password, in general to allow many users to access a data source at once.
Proxy Configuration
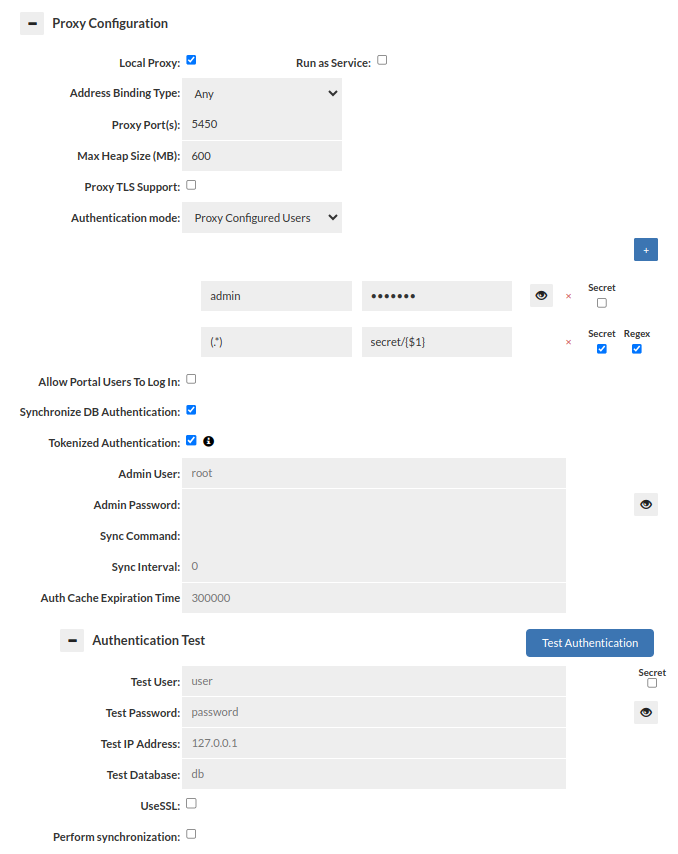
Proxy mode operates by having the management server either start a process on its own, or having a proxy on a remote system connect. Once started, the proxy will open a port that a client can connect to as if the proxy were the database itself, and access data via that process.
- Local Proxy: This option allows the management server to start and manage restarts of a proxy instance on the same server as the management server itself. This option is a great way to simplify the testing of Heimdall in limited environments.
- Run as Service: This option allows the management server to run a proxy as a linux service. It allows proxy to run even while management server is off.
When in proxy mode, several options will be available, two options being required: the address binding type, and the proxy port. The address binding type specifies the behavior of the proxy:
- Any: In this binding mode, all local IP addresses will be bound to, or more specifically, it binds to "0.0.0.0";
- Localhost Only: When this option is set, the binding will be to the 127.0.0.1 IP only;
- Specific IP: This allows a specific IP address to be bound for use. An example of this is to use 172.17.0.1 in a docker container when bridge mode is enabled, so that the proxy can bind for use by any other containers on the same host, without impacting any other proxies that may reside on another host.
Proxy port: The second required option. This specifies the value of the TCP port that the proxy will be listened to. If there is an error binding to a given port or IP, then a GUI alert will be issued when the proxy attempts to start. It is important that the ports do not conflict with other proxies being run on the same host or binding, as only one process can bind to a specific IP:port combination at once. This applies if installed on the same server as a database as well--if the database is on port 3306 for example, than the proxy can not use the same port. You can set:
- single port by typing value of port (for example: 5433).
- multiple ports by separate them by comma (for example: 5433, 5434, 5435).
- range of ports by separate them by minus (for example: 5433-5435)
- mix (for example: 5433, 5435-5436, 5450)
There are several other options available in the proxy configuration as well:
-
Max Heap Size(MB): (only visible if the "Local proxy option is set) The setting for the Proxy java heap memory limit. Default is '600M' which with overhead, will generally consume up to about 1GB of total RAM. This will also result in the setting "Xms" to set the smallest heap size, so as to try to provide more consistency in the "free memory" graph on the dashboard and to ensure that the total memory is always available. Please note, that in distributed proxy mode, this setting has no effect--the java options need to be configured via the user data or heimdall.conf file on the remote instance. For more details of a file
/etc/heimdall.conf, please see heimdall.conf configuration. -
Proxy TLS Support: When enabled, and the client requests it, this option will enable TLS negotiation. Initially, a self-signed certificate will be generated for the proxy, which can then be customized in the Java keystore file in the proxy install directory.
-
Proxy TLS Required: When TLS is enabled, this option will force all connections to connect only with TLS. Any attempt to connect without TLS will be rejected. For Postgres and MySQL, warnings will be provided to the client on the disconnect, with SQL Server, only an alert on the GUI will be presented.
-
Allow Portal Users To Log In: This option is available when Portal Mode is enabled. If selected, before each proxy authentication (for all authentication types except Kerberos), the system will check whether the user is a session user in the portal. If they are and the credentials are valid, they will be authenticated. If the user is not a portal user, authentication will proceed according to the mode selected in the field below.
-
Certificate: Certificate assigned to Virtual Database for TLS connections.
-
Tokenized Authentication: Tokenized authentication is security feature which uses token instead of the database password. This ensures that the proxy will not be bypassed and the database password will not be exposed. This option is available for Proxy Configured Users, SQL Driven and LDAP authentication modes. When using Tokenized authentication with multiple proxies, it is essential to enable an external cache like Redis or Hazelcast. This ensures that all proxies are synchronized and Tokenized authentication works smoothly on all proxies.
-
Authentication Mode: This dropdown allows selecting of the proxy authentication mechanisms. Please see the Theory->Proxy Authentication page for more information on authentication.
-
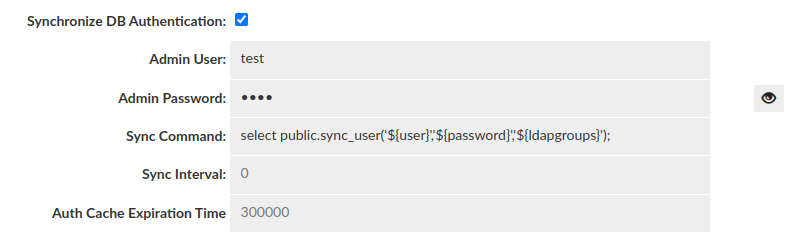
Synchronize DB Authentication: Specifies if synchronization of users and groups should be performed. Moreover, it allows configuring how often the synchronization is allowed to perform after reconnection (Sync Interval) and how long that data will stay in Authentication Cache (Auth Cache Expiration Time).
- Authentication Test: This section allows testing of authentication at the proxy layer. As full SQL based authentication can provide options such as limiting the scope by source IP, what database (these are taken by default from Data Source JDBC URL), or even if you are connecting via SSL or not, this gives a convient UI to determine if an authentication request would pass or fail the proxy layer. Please note--this still requires authentication at the database level, which is not tested via this interface.
There are two basic results that this test can end with:
Authentication successful:
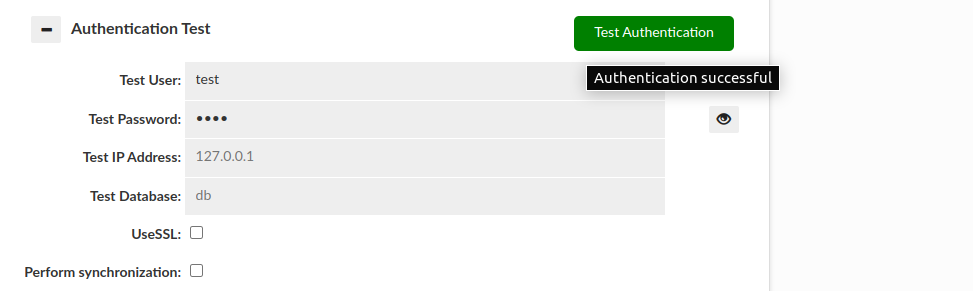
Authentication failed:

- Perform Synchronization:
This section also allows us to perform synchronization of user and groups on test by enabling "Perform synchronization" (Synchronization query is retrieved from "Synchronize DB Authentication").
Then some more results can be observed:
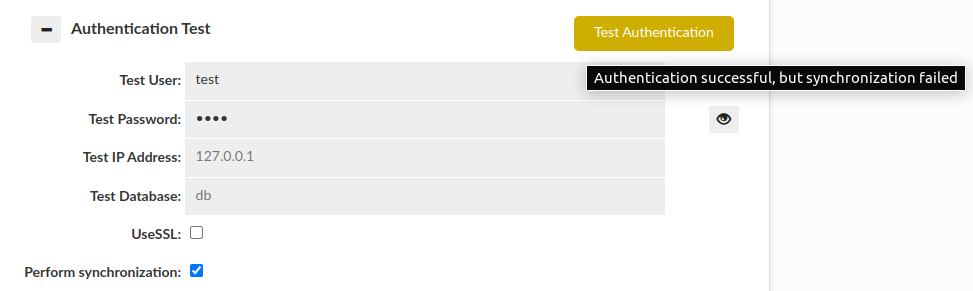
Please be aware that if JDBC URL given in the Data Source contains either ${host} or ${database} respectively Test IP Address or Test Database has to be provided. Anyway, in this case if anything is wrong with the configuration, the additional information will be provided as a hover to the button.
Caching
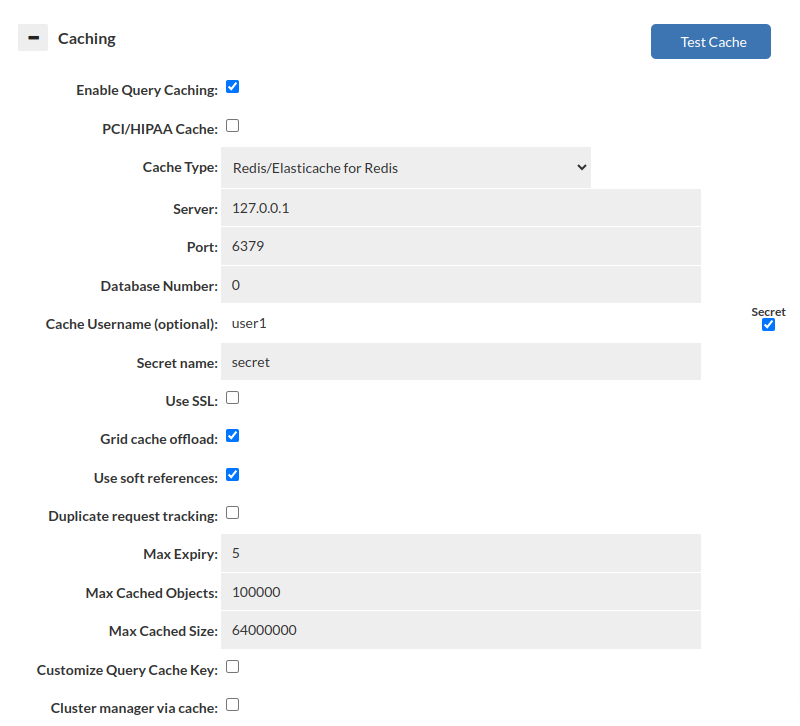
This set of options configures the base cache used by a given VDB. There can be only one cache per VDB at any time, and if the cache settings for a given type are to be changed at runtime, it is required that the cache be disabled first, then enabled again with the new settings. This will allow the cache to be completely torn down, and reinitialized, allowing the entire type of cache to be changed without application restart.
Options (what is visible will vary depending on what type of cache is selected):
- Enable query caching: Check to enable caching–if not checked, no cache rules will trigger caching, although rule processing will be done as normal.
- PCI/HIPAA Cache: When enabled, no cached objects will actually be transmitted to the grid-cache, but the cache will be used to message invalidation requests. This is to avoid transmitting possible sensitive data across unencrypted connections, while maintaining cache synchronization integrity. This option is mutually exclusive with disabling the grid cache offload function, and will remove the benefit of the cache in cold-start scenarios.
- Auto-tune Cache: Enabling this option will enable the cache logic to disable caching in situations where it doesn’t make sense from a performance perspective. This includes if a query pattern isn’t providing any cache hits, or the benefit of the hits that do occur isn’t sufficient to justify caching.
- Cache Type: Select the desired cache type. Options will adjust based on the cache type selected.
- Server: For external grid cache interfaces, specifies the server name or IP to connect to.
- Port: When using an external grid cache, specifies the TCP port to connect to.
- Database ID Number: For Redis, which database "number" is used, not supported when the Redis instance is in cluster protocol mode.
- Cache Password: For interfaces with a password authenticated interface, the password to connect to the cache with. For Redis, value from Secrets Manager can be used instead of this.
- Use SSL: When connecting to the cache, should SSL be used for the connection (Redis)
- Verify Peer: When using SSL, verify the peer TLS certificate
- API Cache Name: For interfaces that utilize a “named” cache interface, this is the name of the cache to use, i.e. Hazelcast.
- Cache Configuration File: When supported, this is an external configuration file to configure the cache, i.e. a Hazelcast client or server XML configuration file. The location of the file should be relative to the current working directory of the JDBC driver or proxy, which will be printed on startup. On a proxy install, when this file is not present, it will be pulled from the Heimdall Server.
- Grid Cache Offload: This option, if enabled, enables a first-tier local cache, which allows hot content to be served out of local heap. In the local cache, the objects will be stored in the performance optimal format (binary streaming format for a proxy, and Java objects when not a proxy).
- Duplicate request tracking: Track the query hash in a temporary list with the same TTL as a cache itself, and only cache if we have a "hit" in this temporary list. This prevents caching of unique queries that will never return from cache.
- Max Expiry: If set to a value above zero, this value (in minutes) is the maximum TTL the L1 cache will cache an object for. This overrides the TTL in the cache rules if it is lower than the TTL set there FOR L1 cache queries. This value does not impact the TTL in the L2 cache such as Redis.
- Max Cached Objects: If set to a value other than 0, this limits the total number of objects in the L1 cache layer to a fixed maximum. This can assist in reducing memory garbage collection time under heavy load, and is advised under very high request volume.
- Max Cached Size: In proxy mode, this setting controls how much of a result-set's transmit buffer is saved before caching is aborted. Any result-set larger than this will not be cached.
- Customize Query Cache Key: This allows the key used to access cached objects to be customized in order to expand when the result is considered the same. By default, all queries will include a hash of the complete SQL query, but also includes the VDB name the request was made through, the database user, catalog and schema. These fields can be removed to allow, for example, multiple VDBs to share the same data in the cache.
- Cluster manager via cache: This option allows a VDB to be managed by multiple management nodes at once, via the cache interface. For this to work, all management nodes must be populated with the vdb, and the cache settings configured to be identical. Once done, configuration changes for that VDB will be synchronized between nodes, and the cache will be used to propagate metrics as well, allowing the dashboard to be used at the same time on both nodes. Further, if one management node goes offline, the access layer nodes will remain unaffected.
- AWS Access Key, Secret Key, Tag, Tag Value: When using Hazelcast with AWS Auto-discovery, these options may be necessary for proper discovery of other Hazelcast nodes.
Note: With Amazon’s AWS Elasticache service, the Redis parameter group option of “notify-keyspace-events” should be set to the value of “AE” in order to optimize cache behavior. This will also be instructed in the log output. For non-Elasticache Redis servers, this option will be configured automatically.
Note 2: Memory allocation for cache is dynamically controlled based on free space allocated to heap. Use the VDB setting of "xmx" to adjust this (in vdb properties). It defaults to target about 1GB of total memory used by the proxy process.
Test cache: The "Test Cache" button allows the user to verify whether a cache connection can be established. Additionally, it checks if key tracking is enabled. If key tracking is not enabled, an alert message will be sent to inform the user about it. After reloading the configuration, make sure to wait for a minimum of 10 seconds as the cache will need to restart. Failing to wait can lead to incorrect test results.
Data Source & Rule List
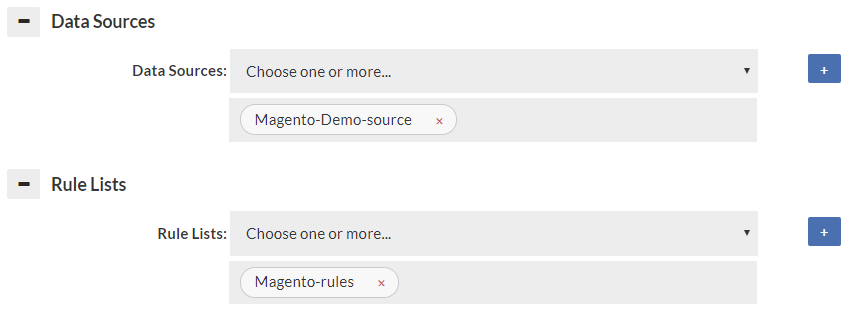
Specify at least one data source, as a default for data to be retrieved from. If a forward policy is specified in the rules for a vdb, it also must be selected here to insure proper connectivity is established to that data source for the forward function to work properly. A connection to the data source will only be established when used if not the primary data source. A reasonable attempt will be made to insure that the data sources for forwarding and read/write split are automatically populated here, but in some rare corner cases (with dynamically generated properties), all data sources will need to be specified here.
Like the data source, the rule list selector configures what rules should be attached to the vdb. If empty, no rule list will be used. All rule lists that are used by the initial (default) rule-list must be specified or they will not be executed. A reasonable attempt will be made to insure that the rules used in "call" actions are automatically populated here, but in some rare corner cases (with dynamically generated properties), all rules will need to be specified here. The log may generate warnings if this is not setup properly.
Note: Only the first rule-list specified will be executed by default. In order for additional rule-lists to be executed, they must be referenced from a rule with an action of call.
Advanced Features
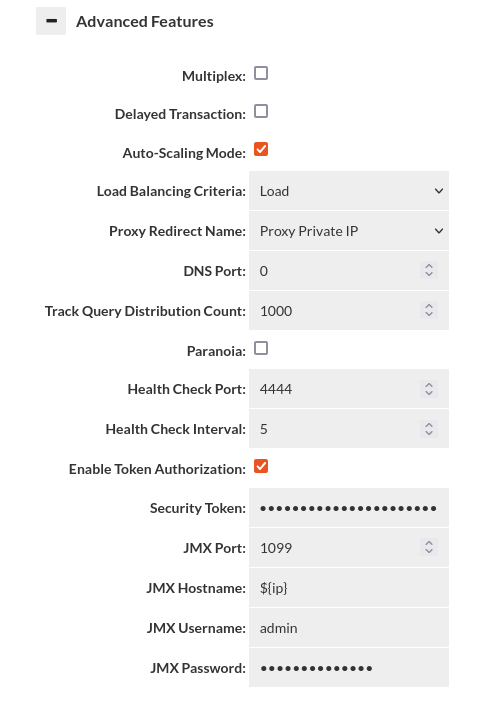
- multiplex: Do load balancing to the server at the transaction level vs. the connection level. This can drastically reduce the number of connections being established to the server. Requires connection pooling to avoid a dramatic performance drop, and may have side-effects that break certain apps. Test carefully before using in production. DelayedTransactions and multiplexing can be used together to improve the query distribution for apps that support them. Examples of features that if used can cause application breakage with multiplexing include Postgres's search_path (then user must execute a query with the full path to the table name), and MySQL session variables. Any "state" will effectively be lost between queries that are not in a transaction when this feature is used. With this option, intelligence is applied to pool in the most effective mode, similar to how PGBouncer provides session, transaction and statement level pooling. Unlike PGBouncer however, you don't need to choose one mode, as it will intelligently switch between modes depending on the situation. As an example, if we determine a temporary table is created, it will switch to session level pooling until the table is released, then switch back to statement level pooling. If a prepared statement is created, this will also happen automatically. This provides the best pooling behavior without additional configuration on the user's side.
- multiplex timeout: When multiplexing how many milliseconds should occur before releasing the connection on the back-end. In general, it is safe to leave this at 0.
- delayedTransaction: (proxy only) Delay when a transaction is started until a DML is detected. This is useful when using a framework that does everything in transactions. Rules set to not match in a transaction will operate until a DML is encountered, then will not match until a commit/rollback. There may be other performance benefits on the server side as well depending on server. Test carefully before production use. If Delayed Transactions doesn't work cleanly, specific queries can be cached or forwarded in a transaction with the in-trans flag instead, but care needs to be taken to use this option.
- Auto-Scaling Mode: (proxy only) Enable to activate auto load-balancing features of Heimdall proxies, for use in multi-proxy deployments. This includes DNS and HTTP based redirects. This option requires external cache (Redis or Hazelcast) configured for VDB in order to work. See below for the options relevant for this feature.
- trackQueryDistributionCount: a count (Long) of the number of query entries to track for auto cache refreshing (default of 1000, requires autoRefresh cache option). Rarely used.
- paranoia=Enable paranoid logging, don't reveal the SQL patterns or queries, only their hashes in debug logs
- healthcheck-port:
If the proxy should do a self-check on itself, and expose the status via the designated port. With an HTTP connection, request /status to determine the status of the proxy. It can be used with auto-scaling set to active/standby mode to redirect all /status requests to active node allowing external load balancers to route traffic only to one proxy and keep other as backup. - healthcheck-interval:
- Enable token authorization: If enabled user that wants to perform api base invalidation will have to provide correct authorization token in request params.
- security-token: Security token should be added to request as parameter for example token="exampleToken".
- JMX Port: If JMX monitoring is desired, set the port here. Typically 1099 if used.
- JMX Hostname: The hostname that JMX uses to refer to itself--the monitoring clients must resolve this name to the Heimdall instance. The value of ${hostname} can be used to map to the internally detected hostname, and can be combined with other string values, i.e. "${hostname}-proxy" could be used to provide proper resolution on a remote client that doesn't have access to the actual hostname via dns.
- JMX Username: The username the JMX client will use to connect to the proxy
- JMX Password: The password for JMX connectivity
JMX Configuration Hints
In the VDB->Advanced section, there is an option to set the JMX hostname. With JMX, it connects twice--once to the name provided by the tool, such as VisualVM, and a second time using a redirect hostname. The hostname must resolve on redirect or JMX will fail. The default value "${hostname}" will use the configured hostname of the VM. This can also be seen in the status tab for the hostname of each VM.
If the hostname does not resolve in VisualVM, then connections will fail. One way to fix this is to use the hosts file on the VisualVM system, or adjust the hostname so it creates a qualified hostname.
Example: If the hostname resolves to ip-10-0-0-1, but you want ip-10-0-0-1.domain.com, you can configure the hostname field in the VDB to be: ${hostname}.domain.com, so when it redirects, the client will be able to connect properly.
For testing purposes, or with only one proxy with a fixed hostname, you can set an explicit hostname here as well.
Additionally, please disable using TLS on connecting, as this option is not currently supported via configuration, as JMX is a rarely used feature, and only internally to a customer's network.
Auto-scaling Mode
When enabled, the following Advanced options become available:
- Load Balancing Criteria: For redirection multiple criteria can be used, the most common of which will be by load. This will select the lowest loaded (by cpu) proxy to receive traffic. Other options include random and active/standby. DNS based load balancing supports all of these options while health check (HTTP) works only with active/standby mode, which redirects all traffic to single node and keeps other ones as backup in case primary one fails.
- Proxy Redirect Name: When redirecting, we can choose to either redirect by the proxy's IP address, hostname or in AWS environment by AWS Public IP. In the case of hostname, this must resolve to all clients connecting as-is, which often won't be the case. In general, the IP address should be used.
- DNS Port: If set to anything other than 0, each proxy will listen for DNS queries on the specified port, and will answer ANY DNS query with a list of proxies to connect to (one in case of active/standby mode), sorted in order based on selected mode (random by default). This can be used in conjunction with the client redirect to remove NLB completely from the database protocol path, yet still provide reliable load balancing. In general, this should be set to 54 to ensure that there is no conflict with any Systemd listener on the host.
Auto-scaling Mode Without an External Load Balancer
If the DNS based autoscaling is to be used without an external LB, a few considerations need to be made. First, the Heimdall system should not have any other processes listening on port 53, including Systemd. Please see your distributions documentation to find how to do this, but it typically requires disabling systemd-resolved, and then setting the NetworkManager to use the legacy DNS behavior. Next, set Heimdall to listen on port 53 for DNS, as inbound DNS requests will use this port. Finally, delegate the shared name you are using as a proxy with an NS record to the Heimdall instances themselves.
As an additional note, with no external load balancer to do draining operations on a transition event, it is highly recommended that the application behavior be tested to ensure that dropped connections will be gracefully re-established. An external LB device can help avoid issues, but even with them, the drain time and max connection lifetime should be in sync to ensure that draining can happen without connection disruption.
Logging
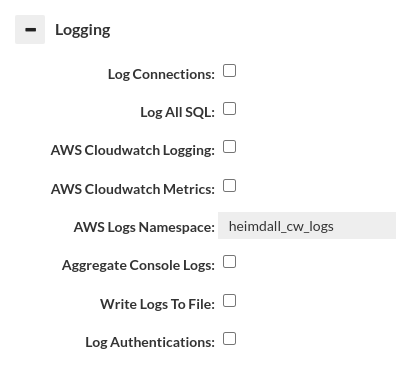
The following log options are available:
- Log Connections: to log when a JDBC or TCP connection is established by the calling application
- Log All SQL: equivalent to enabling a LOG policy with a .* wildcard. If this is enabled, it will override any log rate control configured on a log policy.
- AWS CloudWatch Logging: If in AWS, and selected, then logs generated by VDB instance will be periodically sent to the CloudWatch as a log stream.
- AWS CloudWatch Metrics: If in AWS, and selected, then multiple metric points will be generated under the Heimdall category for the VDB and AWS instance to allow monitoring of the access layer performance. Note, these metrics are generated on a per-minute basis, so may add to the cost of CloudWatch. Additionally, console logs will be shipped to CloudWatch as well when selected.
- AWS Logs Namespace: If in AWS, a name provided as that field will be used as a log group name AND metrics namespace in CloudWatch.
- Aggregate Console Logs: In order to simplify debugging, this option allows console logs from the access layers to be sent to the central manager for logging. When using the "Local proxy" option, this option will be implicitly configured for the management server managed proxy instance, even if not set for other proxies.
- Write Logs to Files: When performing SQL logging, the logs are by default written to an internal database for optimal Analytics speed. If the logs should also be written to detailed CSV logs for each query, please select this option. This may result in a large amount of data written to the log directory, although logs will automatically be cleaned up when that filesystem reached 90% full.
-
Log Authentications: Each authentication attempt will be logged. We will get information about whether authentication succeeded for a given user with the currently selected authentication mode. You can read more about authentication here Theory->Proxy Authentication.
-
Important: When logging SQL, a large amount of data may be generated, and logging can impact the overall performance. To avoid this, you can disable sql logging here, and instead use a log policy with parameters that limit how much data is written. Please see the rules section for details on parameters and the logging section for more details on logging overall.
Debugging

- Pass-through Enabled: When in JDBC mode, the system can be set to pass any NEW connections through to the underlying driver, bypassing all processing logic. This should only be used in rare situations to debug if the system is causing a problem directly, or the existence of the system is causing a problem.
- Verbose Debug Mode: In order to diagnose issues with rule processing or other behavior anomalies, this option can be set in order to track the processing of a query through the access layer. This option can cause significantly performance penalties and should be used with caution.
- Lite Debug Mode: Works similar to verbose debug mode, doesn't log data all the time, instead keeps it in a buffer for up to a second and dumps all records on an exception.
- Log Methods: log all JDBC method calls made by an application, excluding those relating to resultSets. Warning!
- Log ResultSet Methods: Include ResultSet operations when logging other methods. Warning!
Important: When adding in method logging, for every query generated, it may result in a dozen records for JDBC methods, and with resultset methods, every row will likely have one or more log records. Caution should be observed when using these two log options are used, and should in general only be used in low-volume lab conditions.
VDB Properties
Allows a list of name-value pairs to be used to configure various options, in general per direction from customer support, and for use with test releases to enable a fix. Example:
-
suppressNoResult - With Postgres, if an update query is executed via the executeQuery result, it will generate an exception on return saying "No results were returned by the query". In some frameworks, this is detected and suppressed when using the native Postgres driver, but not with the Heimdall driver. In order to work around this behavior, this option can trigger us returning a null instead of a resultset, which appears to allow the calling code to work fine. (true/false)
-
dnsCacheTTL - The cache time (in s) to use for the dns resolution cache, defaults to 5s to conform with AWS requirements. Note: This will impact the global JVM setting for this if used in JDBC mode.
-
dnsNegativeTTL - The time to cache negative DNS (non-existent) queries, defaults to 10s per Java standard. Note: This will impact the global JVM setting for this if used in JDBC mode.
-
delayCacheInit - The time in seconds to delay initializing the cache, normally not needed.
-
reparsePrepared - In cases where prepared statements include dynamic variables, this triggers the reparsing of the expanded query for the purposes of isolating it's base query pattern. This can resolve issues when patterns overflow the proxy or driver memory, or analytics show the pattern with variables included. (true/false)
-
rejectPrepared - As many features end up disabled with prepared statements, it may be needed to reject prepared statements in a QA environment to ensure they don't creep into production code. This will result in an SQL exception if they are attempted. (true/false)
-
syncInterval - Synchronization interval (in ms) which determine after what time the synchronization query will be privileged to be executed after reconnection. Default value = 300000ms.
Proxy only
These properties are applicable only to VDB working in Proxy mode.
-
connectionIdleTimeout - Connection timeout (in ms) for an idle client-side connection, will terminate connection's thread (requires a healthcheck port and interval to function).
-
queryTimeout - Timeout (in ms) for a connection executing a query, will terminate connection's thread (requires a healthcheck port and interval to function).
-
maxConnectionThreads - Max amount of connection threads allowed. Exceeding the limit will terminate the connections that were idle for the longest time (requires connectionsCleanupPercentage property to function).
-
connectionsCleanupPercentage - Percentage of connection threads that will be terminated after maxConnectionThreads limit is exceeded. The excess connection is not included in calculation, for example when limit of 10 connections is exceeded (we get 11th connection), the amount to be deleted is calculated from 10. Setting this property to 10 means 10%.
-
desiredCipherSuite - Forces defined cipherSuite to be used, for TLS connections. All other than defined ciphers will be disabled, use it with caution. Example values: TLS_AES_256_GCM_SHA384, TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
-
extractTlsSecrets - Extract the shared secrets from secure TLS connections for use with Wireshark. Secrets are stored in log folder. To apply this property, Proxy restart is required and Verbose Debug Mode on. Boolean value, default value = false. It is also recommended to enable "Close connections" checkbox in packets capture configuration to close connections so that every connection has secrets extracted correctly for packet decryption. (true/false)
-
legacyEncryptingStream - Uses legacy encrypting streams for TLS and GSS. By default, new streams are used for encryption. If something starts to malfunction, it is possible to revert to the old streams by setting this flag to true. Boolean value, default value = false.
-
ignoreParametersBindingForSpExecuteSql - Ignore binding parameters when executing stored procedure with "sp_executesql". Applicable only for SQLServer Proxy. Boolean value, default value = false.
-
enableBlacklist - Enable adding address to blacklist after many failed database authentication attempts. (true/false)
-
connectionIdleTimeout - Connection timeout (in ms) for an idle client-side connection, will terminate connection's thread (requires a healthcheck port and interval to function).
-
queryTimeout - Timeout (in ms) for an connection executing a query, will terminate connection's thread (requires a healthcheck port and interval to function).
-
defaultTimeZone - Default Time Zone for proxy. Example values: Europe/Warsaw, America/New_York. (Only PostgreSQL)
-
disableSetReadOnly - Disable any kind of SET READ ONLY type of queries. Just log them and ignore. (Only PostgreSQL and MySQL)
Note When using the healthcheck-port option, an additional feature is enabled, that of API based invalidation. Please see the Cache theory section for more details.