Pivotal Greenplum Specific Information
- When using the Async feature, set a connection property of "initSQLAsync" to the value of "set optimizer = off". This will disable the GPOrca optimizer when async is used, which can reduce the overhead per insert significantly.
- If using Postgres offload, ensure that both Greenplum and Postgres use identical schema and user configurations.
- If using foreign data wrappers from Postgres to Greenplum, add a rule as follows:
- Regex: SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
- In-Trans: Checked
- Action: Transform
- Parameter: target
- Value: SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
This will allow the repeatable read transaction isolation level (not supported by GP) to be translated to serializeable, which will enable the Postgres FDW to operate properly
- Ensure that the proper modules for Postgres are loaded in the admin->modules tab.
- When configuring load balancing, specify the failover script (provided), and set the secondary node as being offline. Since Greenplum doesn't allow monitoring of the secondary node, it is up to the script to trigger promotion and enabling the node in the LB configuration.
PG Notify support
This is not currently supported with Greenplum vs. current Postgres sofware versions.
Trigger Invalidation with Greenplum
While Greenplum supports triggers in a limited sense, the triggers do not work when writing to a table from the data segments. As such, trigger invalidation is not yet working with Greenplum (see below for an alternative).
Stored Procedure based Invalidation with Greenplum
As a replacement for trigger based invalidation, a stored procedure can be used that leverages the "Trigger invalidation" mechanism to provide invalidation for Greenplum. When used, the stored procedure can be called after each data load to notifiy Heimdall of new data.
Connection properties to use:
- dbTriggerTracking=true
- dbChanges=select ts,name from heimdall.tableupdates where ts > @ts
- dbTimeMs=select (date_part('epoch', now())*1000)::bigint
Greenplum configuration:
CREATE SCHEMA heimdall;
CREATE TABLE heimdall.tableupdates (
name text PRIMARY KEY,
ts bigint not null );
CREATE OR REPLACE FUNCTION heimdall.changed(text) returns void AS $$
BEGIN
LOOP
UPDATE heimdall.tableupdates SET ts=(date_part('epoch', now())*1000)::bigint where name=$1;
IF found THEN
RETURN;
END IF;
BEGIN
INSERT INTO heimdall.tableupdates VALUES ($1, (date_part('epoch', now())*1000)::bigint);
RETURN;
EXCEPTION WHEN unique_violation THEN
END;
END LOOP;
RETURN;
END;
$$ LANGUAGE plpgsql;
Source Configuration
Below is a screenshot of the default recommended data source configuration for a baseline Greenplum cluster. Details are explained below:
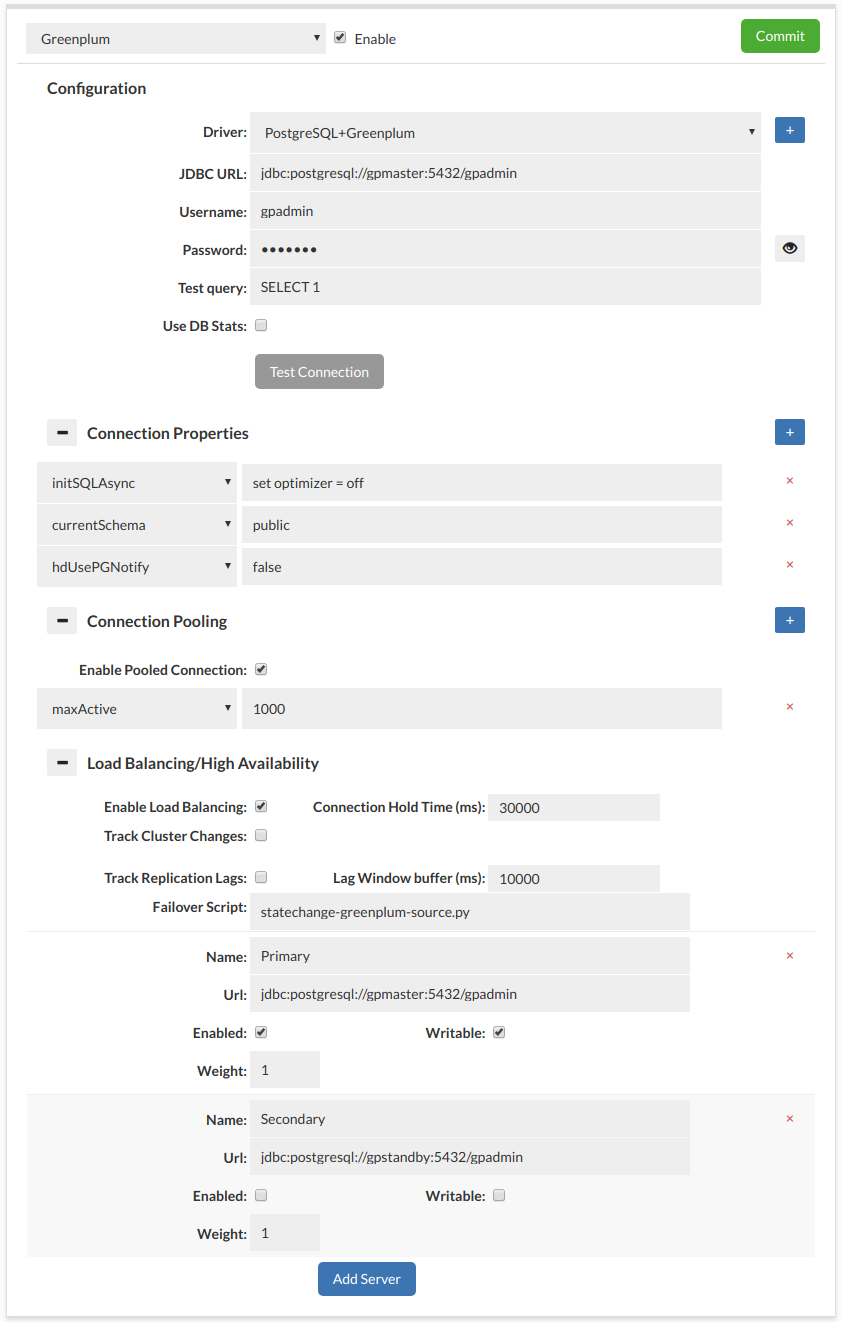
-
Connection Properties
- initSQLAsync: set optimizer = off This is to disable GPOrca optimization when using the Async insert, as this slows down processing for most inserts
- currentSchema: public This can be adjusted, but sets the default schema used when connecting
- hdUsePGNotify: false Postgres supports
-
Pooled Connections
- Enabled to enable connection pooling
- maxActive to set the maximum number of connections allowed in the pool
-
Load Balancing/High Availablility
- Enabled
- Failover Script: statechange-greenplum-source.py
Set your master node as enabled and writeable, and the standby as disabled, and not writeable. After a failover, please ensure that the standby is reset to be in sync and available as a standby per: https://gpdb.docs.pivotal.io/580/admin_guide/highavail/topics/g-recovering-a-failed-master.html