Introduction
The Heimdall Data proxy is a software platform for application and infrastructure owners. Whether on-premise or cloud, Heimdall helps organizations deliver faster, more reliable, and secure content generation. Heimdall Data is a distributed Database Proxy that improves database performance from an application perspective. We give users visibility and control over their SQL environment.
Helpful hint when starting with Heimdall
If you have a ChatGPT account, you can download the PDF version of our documentation, and submit it to ChatGPT 4 or higher as an attachment, then ask questions based on the documentation. We aim to have the documentation complete enough to answer the questions accurately, so this can help in self-serve questions without having to read the entire documentation yourself. If you have a question that is not answered or is incorrect, please let us know and we will update the documentation to account for the missing information.
Use cases for the software
The key use cases for Heimdall database proxy include:
- Connection pooling from serverless applications, including support for multi-user pooling
- Automated caching and invalidation to the cache of your choice (e.g. Redis)
- Read/Write split (i.e. query routing) to reduce load on write-masters in a multi-node cluster
- Improving the performance of DML Ingestion, in particular in Analytics Database environments (Pivotal Greenplum and AWS Redshift)
- Analytics
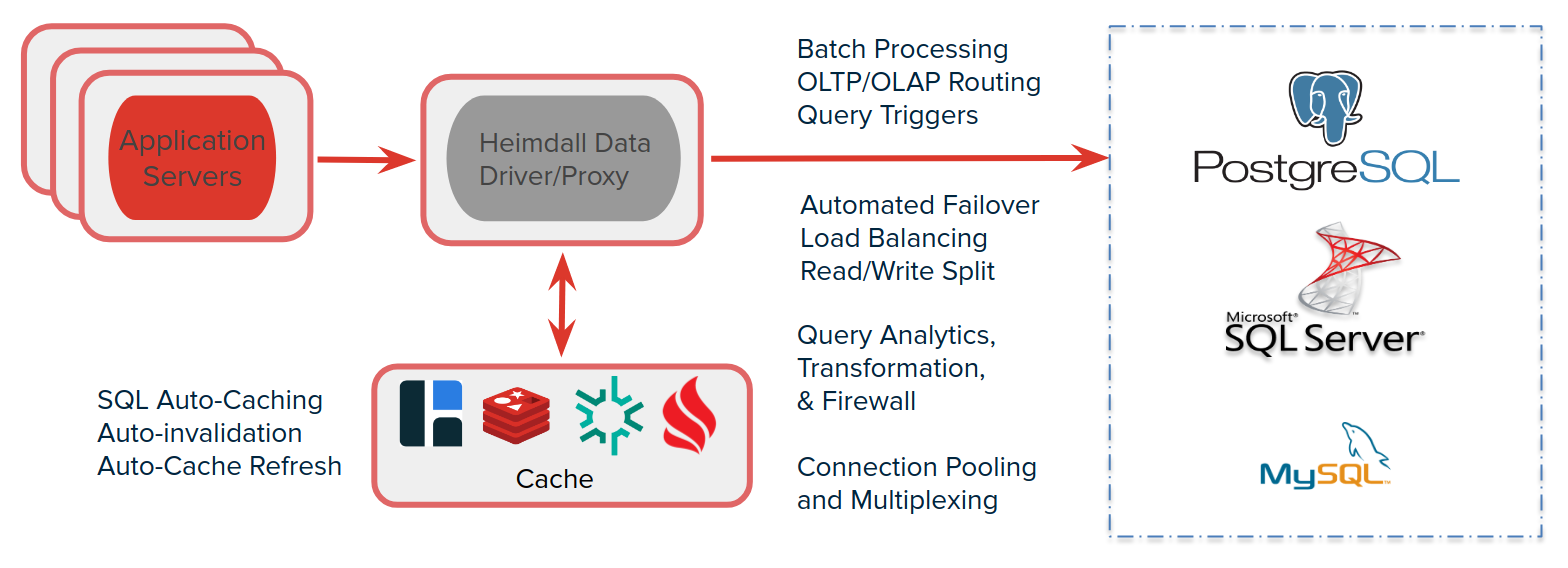
Heimdall supports a variety of databases including Postgres & compatible (Amazon RDS, Aurora and Redshift; VMWare Greenplum, Google Cloud SQL & AlloyDB), MySQL and SQL Server compatible databases. For caching, it supports Hazelcast and Redis.
Caching Architecture
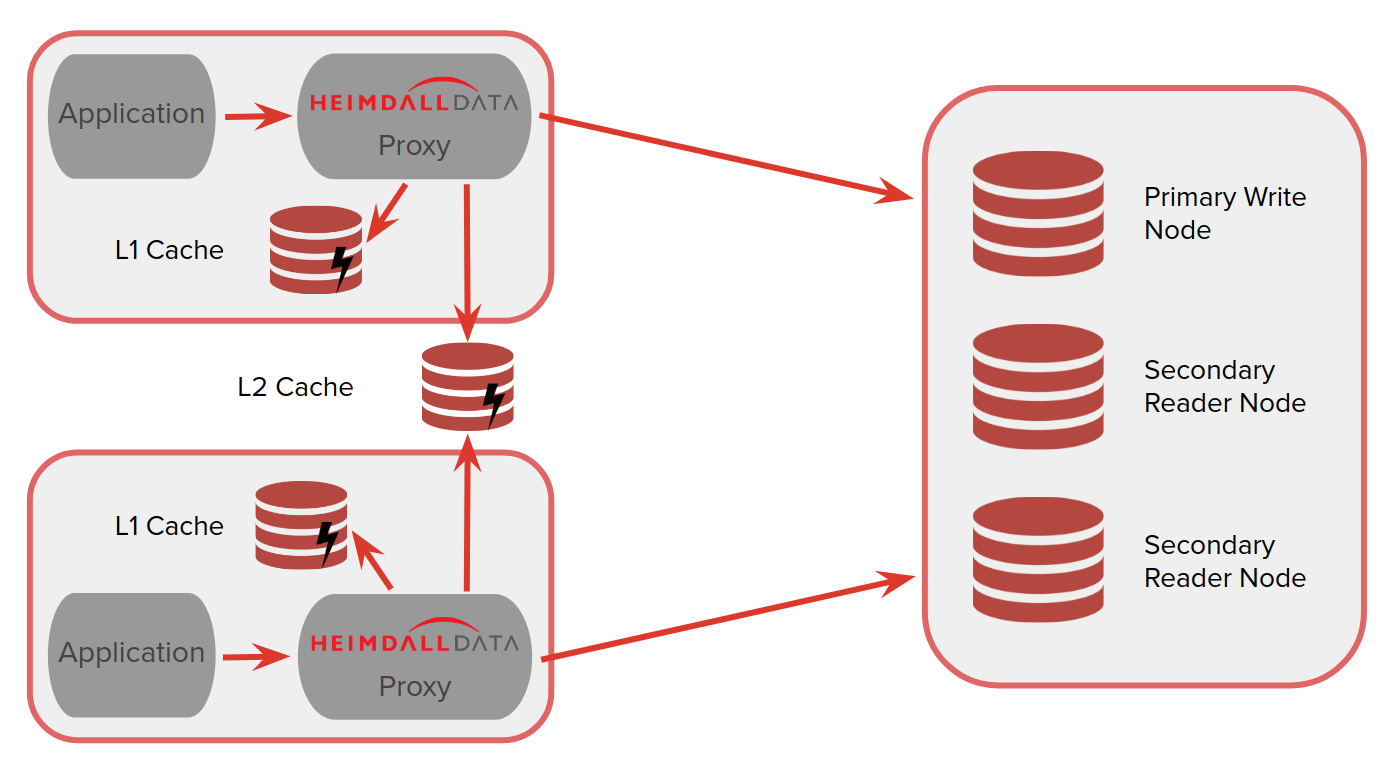
Heimdall optimally operates via a two-layer cache system. The first layer (L1) is an in-heap cache, the size of which is controlled by the heap size in the VDB->proxy settings. The second layer (L2) is used as secondary storage and as a means of communication amongst the deployed proxies. The user will choose any of the supported cache engines to provide a distributed cache between nodes.
Performance Impact
In implementing Heimdall, one frequent question is "what is the performance impact"? This is a difficult question to answer as the variables can be quite complex including:
- Size of requests, i.e. multi-page queries vs. simple single table queries;
- Number of requests/second;
- Size of results and the number of rows;
- If logging is enabled;
- Cache hit rates--the higher the better;
- Number of cores available for processing;
- Number of connections in use at one time;
- Deployment model (centralized vs. distributed), see below;
In a highly optimized scenario with 6 physical cores (12 hyperthreading), with 100% cache hit rate and simple results, Heimdall can achieve over 250k queries/second, WITH the test client (jmeter) on the same host consuming cpu time as well. Heimdall is designed to operate distributed however, so can reasonably scale to nearly any performance level. In most environments, it is suggested that up to 8 cores be used, and that additional scaling based on CPU load be done horizontally, adding additional nodes. In an AWS environment, this can be done in auto-scaling groups to account for surges very easily.
Please note: while jmeter CAN be used to benchmark Heimdall, it is not the proper tool to directly connect to the database to test and validate caching and read/write split. Customers should use their own applications to drive traffic in a lower environment (test). In such a setup, jmeter can be used to generate application load that THEN triggers database traffic through Heimdall. Using applications such as JMeter, DBeaver, or other similar tools will not reflect accurately how Heimdall will behave with other applications so should be avoided for this purpose as a general rule.
Prerequisites and Requirements
In order to install and use Heimdall, the following will be needed:
- A login for the database. For full capabilities, this user should have the ability to login, execute a health check query, access (or create) a schema/database of "heimdall", and have full access to this schema or database. This is used for health checking and various other features such as lag detection.
- Understanding of the configuration of the application, and how to adjust what database it points to. This varies from application to application, but a few common locations for this are:
- The IIS configuration for a .net application, under connect strings
- a configuration json file
- a configuration PHP file
- Preferably a test environment to test with before going into production.
- A Linux server or Docker environment (see below for deployment options) with at least 20GB of space and 4GB of RAM
Supported versions of Linux include vendor supported versions of (in alphabetical order):
- Alpine
- Amazon Linux 2+
- Centos
- Debian
- Oracle
- Redhat/Fedora
- Suse
- Ubuntu
As Heimdall is a Java based program with no cpu architecture dependent code, it can be installed on any architecture supported by Linux and Java. In the case of AWS, the Graviton 2 & 3 instances provides a roughly 30-50% better price/performance ratio vs. the standard Intel VMs in our testing, and should be the first choice in deploying out an auto-scaling cluster. No special instructions are needed to use Heimdall on non-Intel architecture systems.
Deployment Models
Heimdall can be installed as a proxy:

Alternatively, it can be installed as a JDBC Driver (only for Java Applications) and can support other JDBC data sources as well:

For most customers, it is advisable to start with a simple proxy deployment on a single node, and once tested, to work with Heimdall to support more advanced configurations.
In proxy mode, Heimdall supports auto-scaling, multi-zone configurations. It is recommended that in AWS, the AWS CloudFormation Template should be used, which prompts for the various configuration options in order to deploy such a configuration. For other environments, please contact Heimdall support for guidance on how to configure such a configuration.
Deployment Methods
In order to install Heimdall, one of several methods can be used:
- Leverage our single command installer into a supported version of Linux as a single server (documentation)
- Purchase a VM with the software installed from a cloud marketplace (AWS, Azure or GCP)
- Use the docker file to create a docker image (documentation)
- Install into the application as a JDBC driver (please contact Heimdall support for assistance).
For a detailed breakdown on each of the install methods, please see the detailed install page.
One note of importance--all the install methods except a pre-build VM will by default pull our newest version of code from our S3 file distribution site at the time of install except for the manual install option. When installing, make sure that security groups or ACLs do not block this out-bound request. Once installed and online, the system can be locked down if desired see security.
Additionally, the deployment model will impact pricing. In the cloud marketplace images, purchase is based on the size of instance and time used, although many offer a free trial for testing or a free trial can be requested. In on-premises installs, pricing will be direct from Heimdall, and negotiated based on the number of instances used and volume, along with the support model needed.
In most cases, an initial configuration can be made within 30 minutes, and tested using tools such as DBeaver, SQL Server Management Studio, or PGAdmin 2.
Initial Configuration
Once deployed, connect to the server on port 8087/HTTP or 8443/HTTPS. It is recommended that all users leverage the configuration wizard once logged in, in order to do the initial install, as it guides the configuration via a series of questions and prompts in order to build a valid configuration. Please see the AWS specific instructions for information on setting an IAM role for AWS configuration auto-detection.
Once setup, the data source tab provides a test source button to validate access to the database. Likewise, a test VDB option is available on the VDB to pass some basic traffic to the VDB. Note: When using the test VDB option, it requires access to create a new schema or database (named Heimdall) and tables within it. If the data source is not configured with a user that has access to do this, then the test VDB option will fail, even if everything is configured properly for application access.